Vision-Language-Action (VLA) models, trained via flow-matching or diffusion objectives, excel at learning complex behaviors from large-scale, multi-modal datasets (e.g. human teleoperation, scripted policies).
However, since VLAs incorporate diverse data modes in the pre-training stage, and the finetuning dataset often contains demonstration data collected in a kinematically suboptimal or undesirable way, it exists redundant action modes that are irrelevant to the success action modes of the downstream task.
Specifically, we observe a critical inference-time fragility among various sampled noises after supervised finetuning of pre-trained VLAs.
In this paper, we attribute this instability to the distribution shift between the VLA policy and the policy induced by stable success modes of the downstream task dataset.
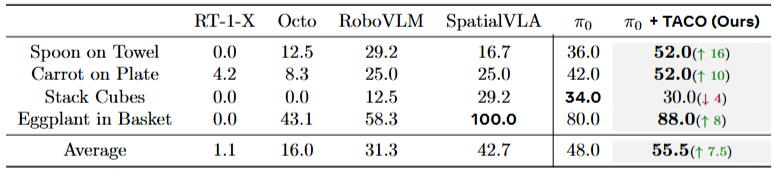
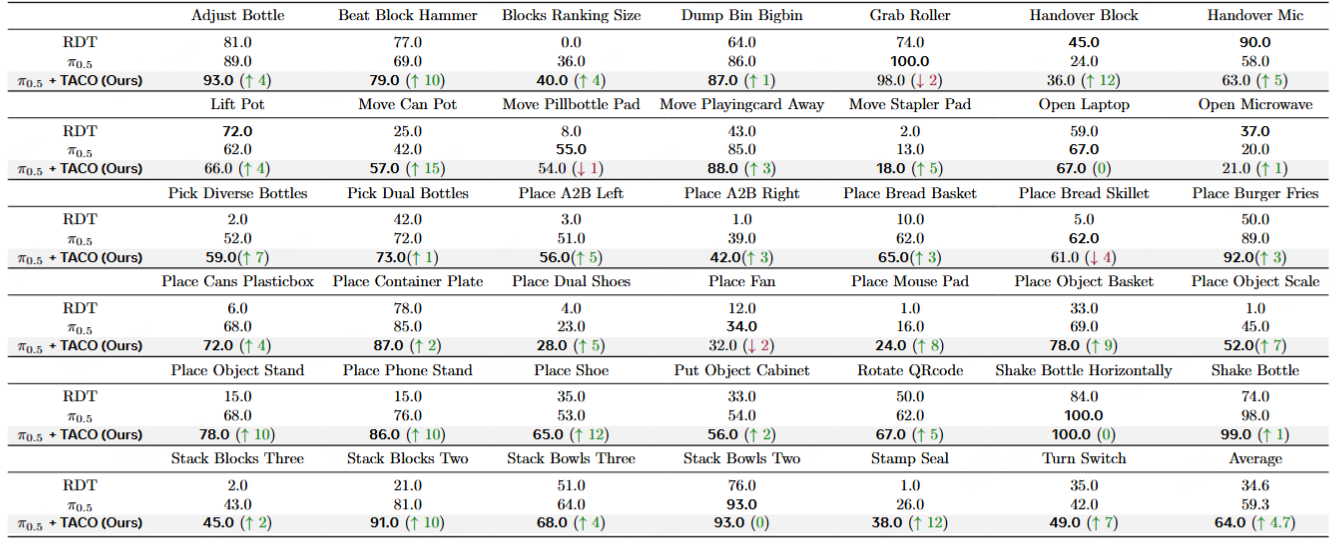
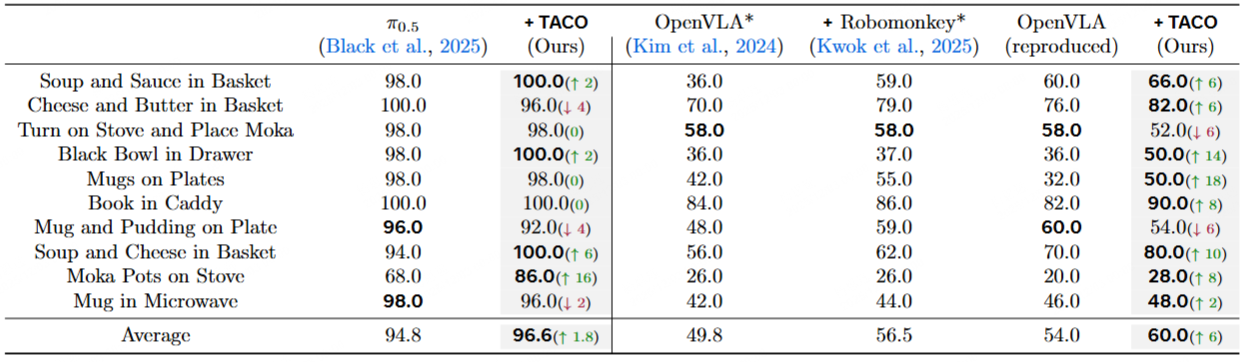
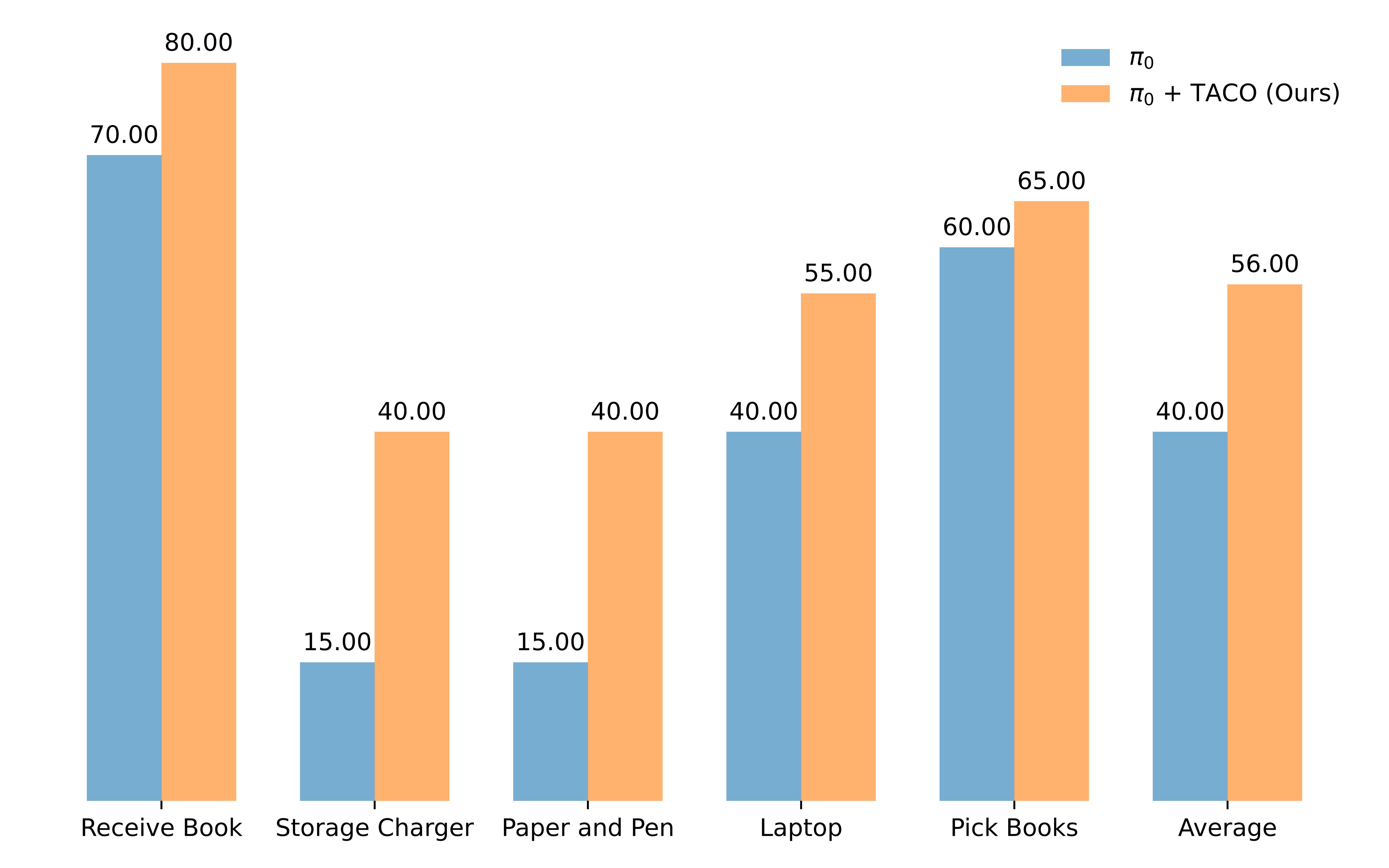
Thus, we propose TACO, a test-time-scaling (TTS) framework that applies a lightweight pseudo-count estimator as a high-fidelity verifier of action chunks. The VLA models integrated with TACO can execute the actions with maximum pseudo-count from all sampled action chunks, thereby preventing distribution shifts while preserving the generalization ability of VLAs since the constraint is applied only during inference.
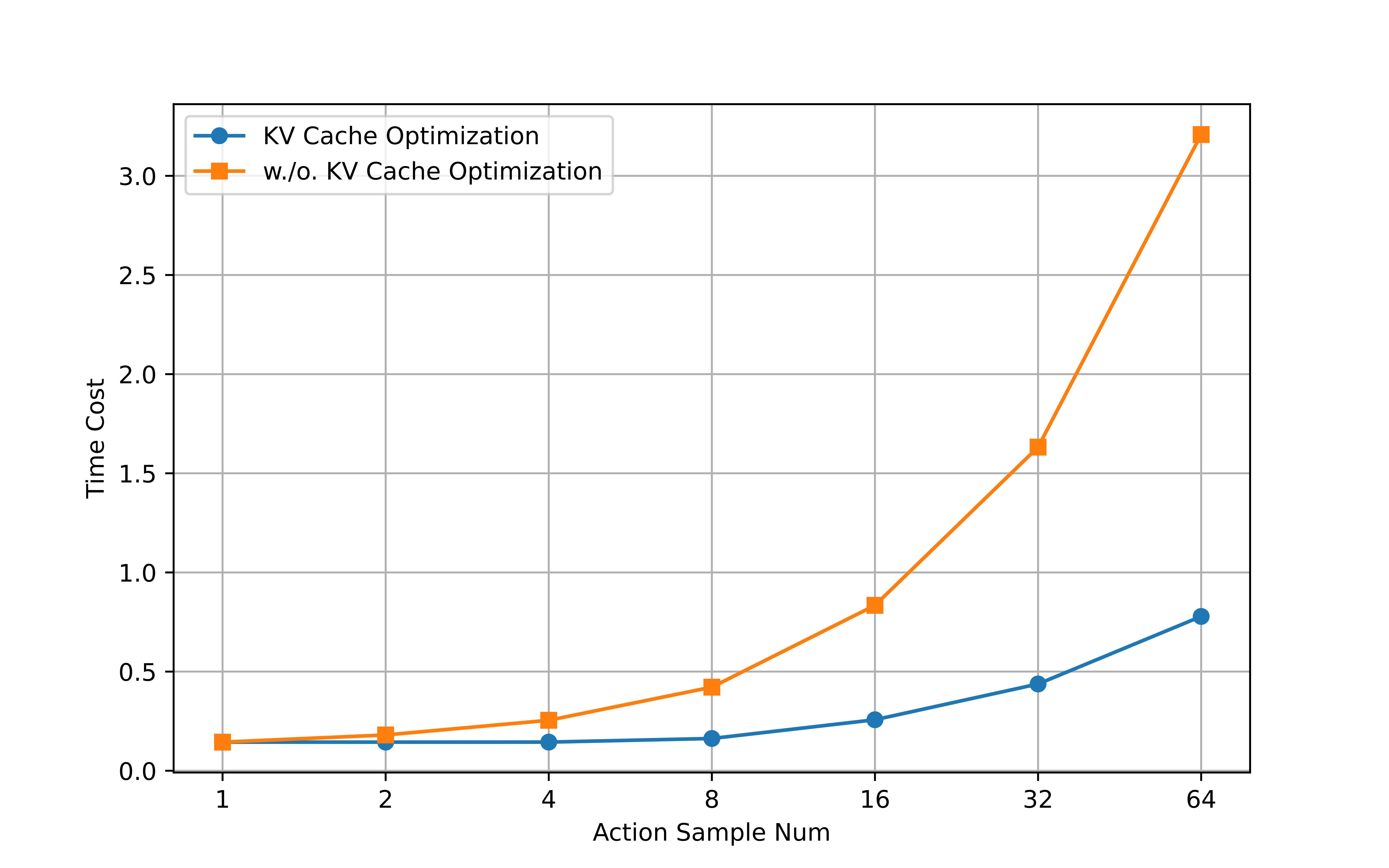
Our method resembles the classical anti-exploration principle in offline reinforcement learning (RL), and being gradient-free, it incurs significant computational benefits compared to RL update, especially for flow or diffusion-based VLAs which are difficult to perform RL update due to denoising process. Extensive experiments across four simulation benchmarks (RoboTwin2.0, Robotwin, LIBERO, SimplerEnv) and a dual-arm platform demonstrate that our method significantly improves the inference stability and success rates in downstream-task adaptations.
 Steering Vision-Language-Action Models
Steering Vision-Language-Action Models